

Disponible pour des missions courtes et ponctuelles jusqu'au 14 août 2025.
À partir du 16 août, engagé sur une mission longue. Des interventions très courtes restent possibles sur mon temps libre — me contacter pour valider mes disponibilités.
Les entreprises disposent souvent déjà de toutes les connaissances dont elles ont besoin.
Le problème n’est pas l’absence d’information — c’est la difficulté à l’exploiter au bon moment.
Procédures internes, documentation technique, contrats, guides utilisateurs, référentiels qualité, FAQ, bases documentaires, données métier — la plupart des organisations disposent déjà d’un patrimoine informationnel important.
Pourtant, retrouver rapidement la bonne information reste difficile. Les collaborateurs perdent du temps à chercher des documents, sollicitent les mêmes experts ou naviguent entre plusieurs outils sans trouver immédiatement ce qu’ils cherchent. Les nouveaux arrivants mettent des semaines à devenir autonomes. Les équipes support répondent en boucle aux mêmes demandes.
Un assistant IA documentaire permet d’interroger vos propres contenus en langage naturel et d’obtenir des réponses précises, sourcées et directement basées sur vos documents — pas sur les connaissances générales d’un modèle IA généraliste.
L’objectif n’est pas de remplacer votre documentation. C’est de la rendre beaucoup plus accessible, exploitable et utile au quotidien.
Ce que vous obtenez concrètement#
- Un accès immédiat à l’information — une question en langage naturel, une réponse sourcée en quelques secondes
- Moins de sollicitations répétitives — les collaborateurs trouvent eux-mêmes sans déranger les experts
- Une meilleure valorisation de vos connaissances — vos documents travaillent enfin pour vous
- Une montée en compétence plus rapide — les nouveaux arrivants deviennent autonomes plus vite
- Une meilleure continuité — les connaissances ne reposent plus sur deux ou trois personnes clés
- Des réponses traçables — l’assistant cite ses sources, vous pouvez vérifier et faire confiance
Votre organisation est concernée si…#
- vos collaborateurs passent du temps à chercher des documents ou des informations
- les mêmes questions reviennent régulièrement — aux experts, au support ou à l’encadrement
- vos connaissances sont dispersées entre plusieurs outils sans point d’accès unique
- certaines expertises reposent sur quelques personnes clés — et c’est un risque
- vous disposez d’une documentation riche mais peu utilisée au quotidien
- les nouveaux arrivants mettent trop de temps à être opérationnels
- vos équipes support passent trop de temps sur des demandes répétitives à faible valeur ajoutée
Une approche centrée sur les usages, pas sur la technologie#
La réussite d’un assistant documentaire dépend beaucoup moins du choix du modèle d’IA que de la qualité des données, de l’organisation des contenus et des usages réellement attendus par les utilisateurs.
Mon approche consiste à partir des besoins métier, des processus existants et des sources d’information disponibles — avant de choisir une architecture technique. Un assistant que personne n’utilise parce qu’il répond à côté ou qu’il est difficile d’accès ne crée aucune valeur, quelle que soit la sophistication de l’infrastructure.
Cette approche est cohérente avec mon parcours en veille stratégique, gestion des connaissances et systèmes d’information : la valeur ne vient pas de la technologie, elle vient de la pertinence de l’information au bon moment pour la bonne personne.
À qui s’adresse cette offre ?#
- PME industrielles et bureaux d’études — documentation technique, normes, procédures qualité, dossiers projets
- Cabinets de conseil et entreprises B2B — offres, études de cas, références, données CRM, documentation client
- Organismes de formation — ressources pédagogiques, référentiels, contenus de formation, aide aux formateurs
- Services support et relation client — FAQ, documentation produit, procédures de traitement des demandes
- Directions et management — procédures internes, référentiels RH, documentation stratégique
Cas d’usage par domaine#
Support interne et gestion des connaissances#
Les collaborateurs interrogent les procédures, les politiques RH, les guides utilisateurs ou la documentation qualité en posant leurs questions en langage naturel — sans parcourir des dizaines de pages.
Support client et assistance#
L’assistant est connecté à votre FAQ, documentation produit ou base de connaissances pour assister les équipes support ou répondre directement aux utilisateurs — réduisant le volume de tickets sur les questions courantes.
Documentation technique et conformité#
Les équipes techniques ou réglementaires interrogent des corpus documentaires complexes — normes, procédures, contrats, référentiels — et obtiennent des réponses contextualisées avec références vers les sources.
Formation et onboarding#
Les nouveaux arrivants ou les apprenants accèdent aux ressources pédagogiques, aux procédures et aux référentiels métier de manière autonome — sans solliciter systématiquement leurs collègues.
Recherche multi-documents#
L’utilisateur pose une question transversale portant sur plusieurs centaines ou milliers de documents et obtient une synthèse contextualisée avec les sources pertinentes identifiées.
Exploitation de fichiers serveurs en équipe#
Votre entreprise dispose de milliers de fichiers sur des serveurs de fichiers, NAS ou drives partagés ? L’assistant IA peut indexer ces fichiers et les rendre interrogeables par toute l’équipe. Chaque collaborateur pose sa question en langage naturel et obtient la réponse extraite du bon document — sans connaître l’arborescence ni le nom du fichier.
Portail de connaissances client ou partenaire#
Un assistant IA sécurisé mis à disposition de vos clients, adhérents ou partenaires pour accéder à votre documentation riche sans parcourir de multiples pages.
Comment fonctionne la solution ?#
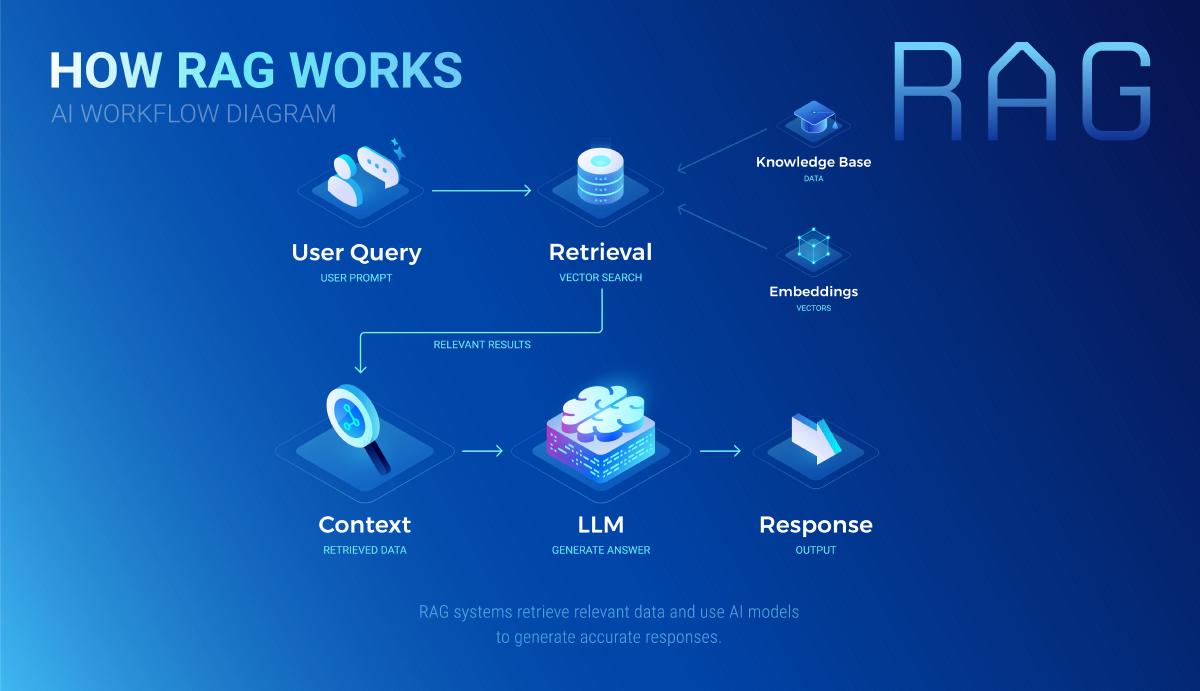
L’assistant ne répond pas uniquement à partir de ses connaissances générales. Avant de générer une réponse, il recherche d’abord l’information dans vos propres documents — c’est le principe du RAG (Retrieval-Augmented Generation).
Concrètement : vos documents sont collectés, structurés et indexés de manière à permettre une recherche sémantique rapide. Lorsqu’un utilisateur pose une question, l’assistant identifie les passages les plus pertinents dans votre base documentaire, puis génère une réponse contextualisée en s’appuyant sur ces extraits — qu’il cite en référence.
Cette approche améliore considérablement la pertinence des réponses et limite les erreurs fréquemment observées avec les assistants IA généralistes qui inventent des informations qu’ils ne connaissent pas.
Déroulement de la prestation#
Phase 1 — Mise en place (forfait)#
Audit et cadrage — identification des usages, des utilisateurs, des données disponibles et des contraintes de sécurité. Cette étape détermine les sources à connecter, les cas d’usage prioritaires, les niveaux d’accès et les indicateurs de succès.
Collecte et préparation des données — les contenus sont collectés, nettoyés, enrichis et structurés. La qualité de cette étape est déterminante pour les performances de l’assistant. Des pipelines d’alimentation automatisés peuvent être mis en place pour maintenir la base à jour.
Construction de la base de connaissances — les données sont transformées et indexées dans une architecture adaptée au projet (voir ci-dessous).
Déploiement de l’assistant — mise à disposition d’une interface conversationnelle selon vos besoins : portail web interne, assistant embarqué dans un extranet ou portail client, interface proche de ChatGPT ou Claude.
Sécurité et gouvernance — droits d’accès, confidentialité, cloisonnement des données, traçabilité des requêtes, guardrails pour encadrer les réponses.
Délais indicatifs :
- 3 à 5 semaines pour un assistant documentaire sur un corpus bien défini
- 5 à 8 semaines pour un projet multi-sources avec intégrations et gouvernance avancée
Phase 2 — Exploitation continue (abonnement)#
Ajout de nouvelles sources, mise à jour automatique des contenus, amélioration de la qualité des réponses, supervision, optimisation et formation des utilisateurs — sous forme d’abonnement mensuel résiliable avec un préavis d’un mois.
Architectures techniques#
Le choix de l’architecture dépend du volume documentaire, des contraintes budgétaires, des exigences de sécurité et du niveau de souveraineté souhaité.
Architecture AWS Bedrock — Amazon S3, Amazon Bedrock Knowledge Bases, Titan Embeddings ou Cohere Multilingual, modèles Claude, Mistral ou Amazon Nova. Idéale pour les organisations déjà sur AWS ou cherchant un service managé robuste.
Architecture ouverte et portable — PostgreSQL + pgvector, Pinecone, embeddings OpenAI ou Mistral, modèles OpenAI, Anthropic ou Mistral via OpenRouter. Adaptée quand la portabilité ou l’indépendance vis-à-vis d’un fournisseur cloud est prioritaire.
Technologies fréquemment utilisées : Amazon Bedrock, Amazon S3, PostgreSQL + pgvector, Pinecone, Anthropic Claude, OpenAI, Mistral AI, Firecrawl, Python
Sources de données pouvant être intégrées#
PDF, fichiers Office, bases de données, sites web, FAQ, SharePoint, espaces collaboratifs, systèmes documentaires, outils métiers, contenus techniques ou réglementaires. Des outils comme Firecrawl permettent de collecter et structurer automatiquement les contenus de sites web ou centres d’aide pour les intégrer dans la chaîne RAG.
Vos fichiers sur vos serveurs sont exploitables. Si votre entreprise dispose de milliers de fichiers répartis sur des serveurs de fichiers, NAS, drives partagés ou espaces cloud — l’assistant IA peut les indexer et les rendre accessibles à toute l’équipe en quelques secondes via une simple question. Plus besoin de savoir dans quel dossier chercher — l’IA retrouve l’information pertinente pour vous.
Bénéfices observés#
- Réduction significative du temps de recherche documentaire
- Diminution des sollicitations répétitives vers les experts
- Meilleure valorisation du patrimoine informationnel existant
- Montée en compétence plus rapide des équipes et des nouveaux arrivants
- Meilleure continuité de l’information — moins de dépendance aux personnes clés
- Amélioration de l’expérience utilisateur pour collaborateurs, clients ou partenaires
Services complémentaires#
Selon votre contexte, ces services peuvent compléter ou prolonger une solution RAG :
- Veille stratégique et intelligence économique — pour alimenter votre base de connaissances avec des informations de veille collectées automatiquement.
- Centralisation des données métier — pour consolider et structurer les données qui alimenteront votre assistant.
- Transformation opérationnelle par l’IA — pour identifier d’autres opportunités d’automatisation IA dans votre organisation.
- Portails clients et espaces collaboratifs — pour intégrer l’assistant dans un espace sécurisé accessible à vos clients ou partenaires.


